

【2019事實查核工作坊/高雄場】報導三:機器學習破解假新聞 人工與科技的結盟
記者黃泓瑜/報導
10月26、27日在高雄舉辦的「假新聞與事實查核工作坊」,邀請了資策會數位服務創新研究所副主任徐毓良,分享利用機器學習(Machine Learning)技術來分析假新聞傳播模式、路徑和文本,以破解不斷新生的假新聞。徐毓良表示,人工智慧與科技技術可以利用比對文本方式,有效地解決假新聞的來源問題,但在技術之外,跨領域的合作才能更有效地解決更上位的問題。
利用人性、同質性糖衣包裹的假新聞
徐毓良先前曾與公視戲劇《我們與惡的距離》團隊,共同利用大數據、資料探勘的方式編劇,他談到,一開始他與製作人分析關於鄭捷事件的內容時,發現當時部分新聞媒體曾報導,新光醫院主任鄭翠芬在鄭捷行刑前一天罵說「那樣也怕痛,你殺了這麼多人,連這種東西也怕痛」,且還強調鄭捷毫無悔意。
徐毓良當時認為,「又怕痛、又毫無悔意」是一個新聞點,便當下記錄這則報導作為戲劇材料,但後來鄭翠芬請學生在PTT發聲明表示,她從來沒有接受訪問,證實為假新聞。製作人認為,他想了解新聞是如何報導無差別殺人事件的內容,因此,他利用資料探勘,挖掘各媒體小編是如何帶風向、在報導內容中經常提及的角色與形象是那些,再加上戲劇團隊執行田野調查的結果,才發現媒體角色能夠影響人們的認知。

徐毓良舉出,最早利用媒體影響民眾認知事件,是1938年美國哥倫比亞廣播公司製作《火星人入侵記》,原本小說的版本是以英國為背景描述,但主持人想要用更生動、真實方式呈現,故把英國替換成美國紐澤西州,且刻意在節目中安排新聞插播,造成紐澤西當地民眾恐慌,這是歷史上最有名的假新聞事件。他也舉例,2018年劍橋分析事件利用在Facebook的心理測驗,暗自蒐集5,000萬位Facebook用戶個資,也包括喜好、性格等,應用在當年美國總統大選候選人川普的宣傳策略中,主要投其特定群體的行為與喜好,來傳達特定的訊息,包含假新聞和半真半假具爭議性的新聞。
這類假新聞宣傳手法,除了影響政治層面,也會影響健康與品牌形象,徐毓良表示,去年2月台灣發生衛生紙之亂、9月關西機場事件和常見健康醫療謠言等爭議的內容,大部分都由上游組織投入資金來操弄資訊,如公關公司、政治團體、企業組織和國家組織等,中間再利用媒體工作者、網軍來製造訊息,傳布在內容農場、媒體、搜尋引擎或社群媒體等傳播管道,鎖定特定閱聽群體來傳達假訊息,來達到其政治或商業目的。
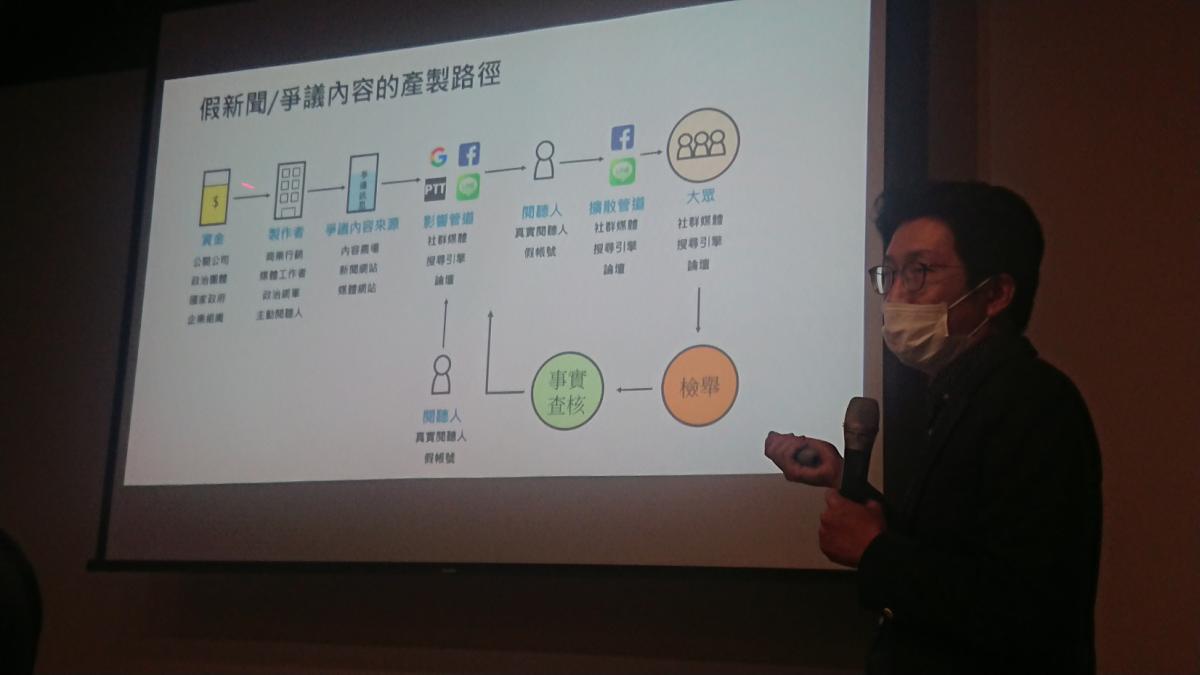
從人工到機器學習的事實查核
徐毓良指出,要用自動化方式來偵測假新聞之前,一定要先建立資料庫來讓機器學習,資料庫需要包含:第一,真假新聞比對,若同樣一件事情,如果沒有真的新聞與假的新聞,電腦是無法學習辨別,這部分需要依靠專業人士,找出數則議題報導,分類真假新聞,再要求電腦學習假新聞的型態,這部分是最重要的工作。
第二,可被分析的文本格式;第三,文字資料長度、風格;第四,主題類型分類,不同類型有不同寫作方式,也有不同傳播軌跡,例如政治報導與健康報導的寫作方式不同;第五,資料搜集時間定義;第六,資料背後的訊息,包含版權、來源、作者等,Facebook就是利用這項技術來標記可信的媒體來源,若資訊是來自不明的消息來源,或是可信度較低的媒體,Facebook在排序上安排較低的位置;第八,新聞內容描述方式;第九,資料庫是可被驗證;第十,語言和文化因素,但目前開發較多都是英文資料庫,中文資料庫較少。
徐毓良進一步表示,目前機器學習比較容易學習的假新聞類別,分別是陰謀論、偽科學、誤導資訊和捏造的虛構訊息等,雖然假新聞會演化,但在內容或形式上都會有相同的「根」,透過機器學習都能抓得到8、9成的錯誤和虛構訊息。但他也坦言,政治宣傳與政治資訊是現今機器學習不容易學習的類型。
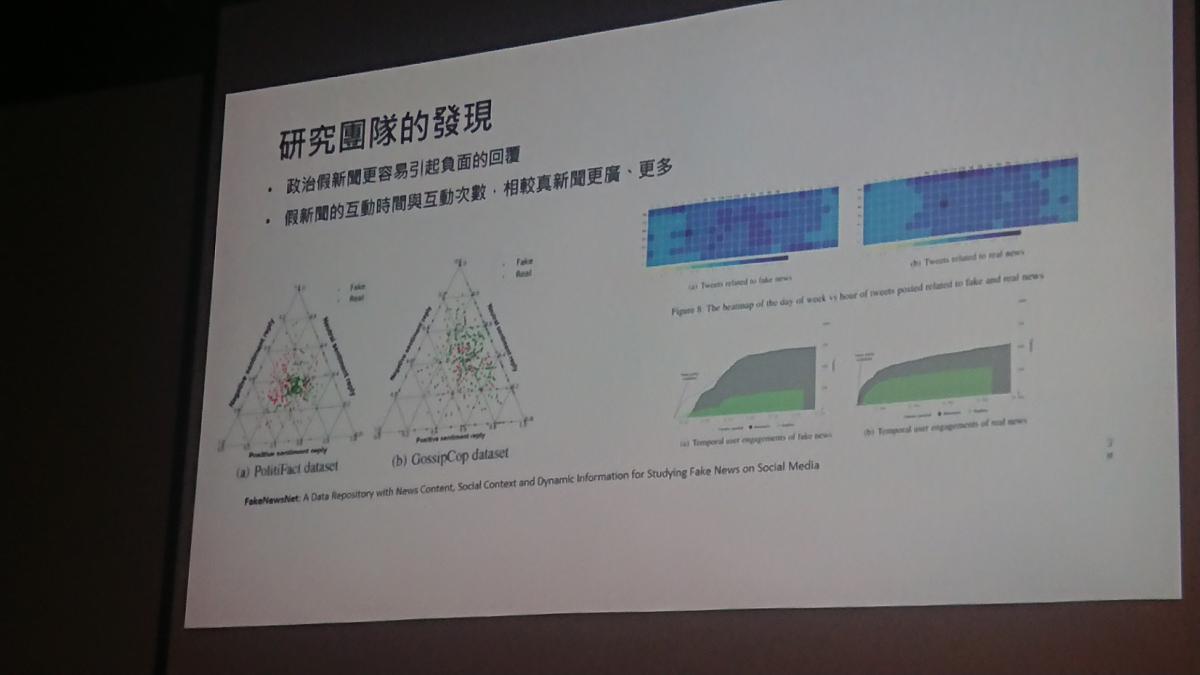
徐毓良接著介紹國外名為「Fake News Net」的假新聞資料庫,這項資料庫蒐集報導是八卦和政治新聞為主,且是在推特上面的訊息,內容包括訊息的ID、發布者推特的ID等。比較特別的是,Fake News Net加入訊息時間與擴散性的維度,能夠了解訊息傳播路徑與軌跡。Fake News Net研究團隊發現,政治性的假新聞容易引起負面的回覆,以及互動時間與互動次數,與真實新聞相比較之下更廣、更多。除此之外,他們也發現八卦新聞不太會影響人民看待事件的看法,政治性的假新聞容易操弄人民的認知與對立的情緒。
除此之外,徐毓良介紹美國一家專門從事媒體研究的非營利組織Credibility Coalition,他們研究媒體可信度調查列出2大指標來分辨資訊真偽,分別為情境指標和內容指標。情境指標需要觀察目標包含是否此資訊是否為原作、是否經過事實查核、引用是否有代表性、引用來源的好壞、廣告數量、強烈要求讀者轉發文章的數量、垃圾廣告、要求轉發的位置。內容指標則是標題、引用專家意見、引用機構權威度、文章的語調與推論等。
徐毓良特別指出,Credibility Coalition建立的指標亦考慮到商業的因素,商業因素加入分析指標中,更能發現這些商業因素是占這類網站很大版面,也是該公司從事假新聞最重要的原因,例如內容農場。

破解假新聞需跨領域技術的合作
徐毓良解釋,電腦判別文章的真假,需要從文章內容的語彙(lexicon)、語法(syntax)、語義(semantic)三方面來檢視。
從文章語彙當中判別假新聞,可以從文章用字規則、用語和出現最多的詞彙來建立詞袋模型(Bag-of-words model)。再者,從用字的心理學語言特徵來看,可以分析文章中的積極情緒用詞、功能詞、代名詞和情感、社交詞來判別,假新聞經常使用社交和正面詞語。另外,國外有研究發現,假新聞的標題與內容與真實新聞相比,多數會使用驚嘆號和問號。除此之外,假訊息通常使用較低層級、較簡單的文字,擁有較高的可讀性。最後,假新聞語法結構與真新聞結構不同,例如,使用指使語句。
電腦除了從文章內容來分析假新聞外,徐毓良也指出,從社群使用者的留言也可判斷真假新聞,包含留言內容的表情符號多、髒話多,具體主題的討論少,主觀性描述比較多,以及一面倒的正面評價通常都是假新聞,但如果是使用者是發表個人意見(如,我認為是……)假新聞可能性相對較低。
然而,徐毓良表示,目前台灣尚未建立假新聞比對資料庫,這是正在朝向的目標。另外,他認為,沒有任何東西都是技術或科技的問題,雖然機器學習可以透過比對真假新聞報導內容來破解假新聞的文本形式,民間有事實查核組織來查證假新聞,但這些技術只是在堵住水壩的水,最嚴重的問題還是屬於上層的問題,包括特定組織的資金投入假新聞、製作者和訊息來源,這方面需要不同領域的合作,擬定法規或政策來解決。

